読んだ記事とメモ
読まなかったブクマ・読んだブクマ・面白くなかったブクマ・有用なブクマなどの管理がしづらくなってきたので、「読んだ記事アルバム」のようなものとしてまとめていくことにしました。 特に新しい記事のみという訳ではないので、雑多にまとめてこの記事に追加更新していく予定です。
個人的な備忘録なので今後の取扱をどうするかまだ決まってませんが、とりあえず走り出しということで。
インフラ
- Cloudflareが「Fastly(Compute@Edge)よりも3倍早い」と言った記事に対するFastlyの反論記事
- エッジネットワークの相対的なパフォーマンスの測定は容易ではない
- TTFB以外に必要な計測のための要素
- killコマンドはSIGKILLを送信する
- 引数を渡すことでSIGHUPだったりSIGINTだったりを送信できる
- プロセス単位でデフォルトの挙動が上書きされていることがある
- SIGKILLを送信されてもkillされないプロセスというのも存在し得る
- pumaはSIGHUPを受け取るとログファイルをリオープンする仕様になっている
JS
github.com React18におけるsuspenseのRFC。
Start Date: 2022-03-23
- Suspenseは、コンポーネントツリーを表示する準備がまだ整っていない段階で、コンポーネントツリーの一部のloading stateを宣言的に指定することを可能にする。
- React16.6.0の時点では、suspenseはクライアント上でReact.lazyを使ってcode splittingをするためだけのものだった。
- suspenseがどう動くか
- renderの状態ができていないことを表す。
- dataの取得方法によらず、Reactにdataのloading stateをさせることができるので、コードとdataのloadingstateを完全に分離できる。
- Behavior change: Committed trees are always consistent
- renderingに関する処理順序・手法が一部変わった。
- New feature: Server-side rendering support with streaming
- 元々は、SSR中にsuspendするとエラーになっていた。
- 新しい手法(stream形式でのrenderer)では、準備が完了していない一部HTMLツリーにfallback HTML(例えばspinner)をemitすることができる。
- 準備が完了した段階で、同じstream上の短いインラインscriptを使いオリジナルのDOM構造を差し込む。
- streamとは別の話だが、suspenseを使うことで、hydrationは全てのcode-splitting chunksのloadingを待つ必要がなくなる(main bundleが準備できたらすぐにhydrationできる)。
- 欠点として、synchronous SSR render(stream形式ではないrenderer)を使っているであろうlibraryについては異なるアプローチを考える必要があるかもしれない。
- New feature: Using transitions to avoid hiding existing content
- 例えば、タブUIでタブを切り替えた時、新しいタブのコンテンツが準備できていないのであればsuspenseのfallbackが表示される。
- fallback表示が気になるのであれば、
startTransitionAPIを使ってタブの切り替えを行うと、新しいタブのコンテンツが準備できるまでタブの切り替えを待つことができる。 - fallbackがないとユーザーが混乱するかもしれないので、
startTransitionとセットでuseTransitionAPIのisPendingを使うことで、インタラクティブなUIを維持できる。 - suspenseはネストで利用できる。
- transitionのdurationをマニュアルで設定する方法はない。
- Behavior change: Layout effects re-run when content reappears
- 再度タブUIでタブ切り替えを考えると、suspense状態のときにタブ内のコンテンツ量はわからないため、layoutに影響を及ぼす。
- layout effectsを実行することで解決できるはず (<-手法が理解できなかった)
関数をsetStateに渡す手法。
複数のsetStateを非同期に行いたくない場合、関数を渡すことで、stateの更新や更新に関する値の取得を行うことが意図した順序かつタイミングで行うことができる。
- useRefの返り値の型:RefObject or MutableRefObject
- どっちの型をどの場面で使うべきか?
- インスタンス変数代わりに使う時、DOMやコンポーネントにアクセスする手段として使うときなど
- Module Record
- Abstract Module Record
- Cyclic Module Record
- Source Text Module Record
- (それぞれ別々のものという訳ではない)
- TSでしか書けないCSS in JS(TS)
- EmotionよりもTSに対する親和性高そう
- useStateではなくuseReducerを使シーン(状態更新が複雑なシーン)について
- 複雑さの判断ポイント
- 更新処理トリガー
- 更新条件
- 更新ロジック
CSS
- コンテナクエリ(@container):親コンテナのサイズによってスタイルを変える
- カスケードレイヤー(@layer):詳細度が高くてもレイヤーのスタイルを上書きできない仕組み
- color-mix, color-contrast:カラーの混合やコントラスト基準を満たすカラー選択が可能になる
#Glaphics kamino.hatenablog.com
- OpenGLはラスタライズ前提
- ラスタライズ方式:描画したい図形や物体を2次元平面(カメラ画像平面)に射影することで画像を生成。物体相互の影響考慮がされない(自分で影を配置してあげる必要がある?)。ゲームなんかはラスタライズが多い。
- サンプリング方式:光の反射の軌跡をシミュレート。レイトレーシングとかはこの方式。リアリティは高いが計算ロジックに工夫が必要。
- OpenGLでサンプリング方式でレンダリングするする場合工夫が必要
- GLUI, freeglut, GLFW
- Vulkanは複雑
サービス
長文要約AI
かけだしピープルマネージャーとしての2021年振り返り
明けましておめでとうございます。
2021年を振り返ると、社会人経験の中でも比較的、未知分野の業務を行う年となりました。その中でもマネジメント業務に関しては試行錯誤しながらチャレンジを行う一年となったので、今後に活かせることを期待しつつ一年間の行動・結果・考え方の変化などを振り返っていこうと思います。
前提として、エンジニアのマネジメント = エンジニアリングマネジメントと想像する人は多いと思いますが、個人的には、エンジニアリングマネジメントという業務はその下位レイヤーにあるいくつかの役職をまとめたものだと考えています。
他記事からの引用ですが、以下のような分類になるイメージです。
・ピープルマネジメント ・テクノロジーマネジメント ・プロジェクトマネジメント ・プロダクトマネジメント
本記事ではピープルマネジメントの話に絞って書きます。各種マネジメント業務の定義については以下記事が非常に分かりやすく書かれていますので、そちらを参考にしてください。
ピープルマネジメントについてですが、ざっくり言うとチームビルディングや採用に関する業務です。その他、組織に関する良いところや課題などの意見を社員から収集し、組織体制を整えるための計画・実行などを行います。
実行したアクションと考察
社員の給料を上げるためには
マネージャーとして一番最初に行ったことは、目標の制定と、その目標を達成するためのタスクリスト作りです。
会社自体のフットワークが軽く、マネージャーとしての動き方が決まっている訳でもなかったので仕事はすべて自分で考えて実行する必要があったのですが、目標を決めなければ何をすべきか分かりません。そのため、第一に目標を決め、そこから何をすべきかを逆算していくことにしました。
品のない表現になりますが、会社員としての仕事を要素分解すると「いかに稼げるか」に尽きます。エンジニア単体で考えると、「いかに仕事を早く終わらせられるか / いかに難しい課題を解決できるか / いかに想像し難いアイデアを打ち出せるか」といったものになるでしょう。このあたりのサポートを行うのがエンジニアリングマネージャーの仕事だと思うのですが、ピープルマネージャーとしては「稼ぐための施策をいかにエンジニアが実行できているか」という事柄が重要になります。稼ぐためのビジネスプランは組織全体で考えるものですが、そのビジネスプランという名のレールを走り続けるモチベーションを維持し、レール上で止まってしまった人やレールから逸れた動きをしている人が出ないようにする、というのがピープルマネージャーの主な仕事だと考えています。
モチベーションについてはとりあえずお金がないとやってられんでしょうということで、私の2021年の目標は「社員全員の給料を上げる」ことに決めました。(結果としてこの目標は達成できませんでした。詳細は記事末に記します)
給料を上げるためには組織の経常利益を増やす必要があります。私が所属している部署では受託開発がメイン業務となるため、利益を上げるためには「開発人員の単価を上げる / 社員を増やす 」という手段が候補に挙がります。 (別件として仕事を受注し続けるというのも重要ですが、ありがたいことにそこは既に達成できており、開発リソースがないためお断りするという状態でした)
「開発人員の単価」を上げるという目標達成のため、まずは主に単価の低い新人エンジニアをフォローすることにしました。また、弊社の場合はクライアントに対してリード・提案をしていくオーナーシップも求められているので、そのあたりのプロジェクトマネジメントや顧客折衝のためのコミュニケーションなどについてもサポートしていく必要がありました。すでに新人よりも水準が高いエンジニアについては自分の得意な分野を伸ばしてもらうように伝え、フォローはテックリードに依頼しました。
「社員を増やす」という目標については会社のブランディング化が必要だと考えました。元々弊社ではリモート・フルフレックス可能というのが強みだったのですが、今となってはフルリモートは当たり前の時代です。フルリモート・フルフレックス以外の強みや魅力を打ち出さなければなりません。開発部の情報をより詳細に伝えるため、テックブログを通じた外部発信やコンパスでの勉強会開催を増やしていくことにしました。
毎週1on1を行うメリット
上記目標の達成についてサポートするため、毎週1on1を行うことにしました。
私がマネージャーになる前は、1on1は希望者のみに実施されていたのですが、「レール上で止まっている人 / レールから逸れている人」を迅速に見つけるために毎週定期的に行うことにしました。実際に行ってみて、自分の行動が成果を出せていないことに気づけない人は意外と多く、最短一週間で軌道修正できることは大きなメリットでした。また、課題に対してどういうアプローチが適切か答えが出ないような場合に、「とりあえずこの方法でやってみよう(上手くいかなかったとしても一週間後にまた考え直せば良い)」という感覚でカジュアルに行動を決められることも良かったです。
副作用的な話ですが、フルリモート勤務のため同じプロジェクトの人以外は話す機会がなかったものの、一週間に一回は「最近どう?」的雑談をする機会ができ、個々人の意見や問題を抽出するためのイベントとしても機能しました。ただし、本来1on1というものは強制的に行うべきものではないはずです。その人自身が課題を持っていない場合に1on1をしてもただ言われたことをやるだけの進捗確認イベントになってしまいます。今回の場合、課題を見つける力の弱い新人エンジニアのみ定期的に1on1を行い、その他エンジニアについては日常的な雑談で解消していました。このあたりは組織の状況に応じて1on1に何を期待するのか明確にした上で、フレキシブルに実施するのが良いかと思います。
ただ、日が経つにつれ私自身の業務負担がきつくなったため、現状、1on1は隔週で行っています。
互いにフォローし合えるためのチームビルディング
業務負担がきついという流れの中で、各種フォローを社員同士で行ってもらえればより良いな、という考えが生まれました。「誰々さんよりも誰々さんの方が話しやすい」という状況は誰にでも発生しうるし、私よりも他の人の方が話しやすいのであれば自発的に他の人同士で相談し合ってもらった方がより良い成果につながります。さらに言うと気の合う人同士の相乗効果で勉強会イベントの発生や新規プロダクト提案などがされるようになれば理想的です。
ただ、フルリモートということもあり、そもそも話したことがないという社員の組み合わせがほとんどでした。会社で利用しているDiscordサーバ上には「雑談」というルームがあり、時折そこで雑談をしたりして一服するのですが、雑談ルームに入ってくる人はほぼ決まっています。雑談ルームに入らない人同士で話す機会は基本皆無で、「自発的に相談し合える人」という存在も見つけづらくなっていました。
そんな中、同種の課題を持っていたであろう上層部から「業務中でも交流のためならゲームして良い(むしろ強制でも可)」とお達しを受け、月一で部署内でのオンラインゲームイベントを開催することになりました。ただ、参加者の多くは雑談ルームに入ってくる人で、ゲーム選びも参加者のプレイヤースキルに合わせる必要がありました。コミュニケーションが発生しつつ、全員プレイ可能なハードウェアを所持しており、操作スキルが重要ではなく、無料でプレイできるゲームというものがほとんど見つけられませんでした。
毎月ゲームを探しつつイベントを開催していましたが、条件を満たすものはAmong Usというゲームのみとなりました。
上記ゲームは、ある程度人数がいないと面白さを発揮できないということもあり、定常的に参加者を集めることが難しく、スケジュール調整のコストも相まって運営を中止することにしました。イベントとしては当初の目的は果たせませんでしたが、他部署との交流機会となり、イベントを続けることの難しさも学ぶことができたため、個人的には良いリターンがあったと思います。
イベント運営側としては初めに「どうすればみんな参加してくれるか」を考え続けていましたが、そもそも参加対象となる人たちがイベントに意味を見出していなければ意味がありません。どれだけ時間を使って試行錯誤しても参加者が増えなければ運営側も疲弊するだけです。誰も得をしません。実のところ、興味のない人にとって、興味のないイベントはどうやっても興味を持てないのです。
基本的にこういったイベントについては「やりたいことをやり続ける」のが一番だと感じました。参加者が来ることを期待せず、誰かが来ればラッキー程度の考えで良いと思います。そうやって会社の中で勝手にやりたいことをやっていれば、「自分も何かやってみよう」という空気感が醸成され、各々が自発的に動き出し勉強会や趣味の部活動的なものが発足し始めることを期待しましょう。
上記反省を活かし、今は毎月個人開発で作ったアプリ(その他なんでも良い)を見せ合うイベントを毎月開催しています。自分としてはそのイベントに向けてネタを考えたりアプリを作ったりするのは楽しいですし、誰も来なくてもインターネット上に公開すれば誰かしら見てくれるので損はないなと思っています。他の人が参加してくれれば、追えていない技術トレンドや開発の苦労話などが聞けてなお面白いです。ありがたいことに、毎回誰かしら来てくれるのでイベント自体は1年間継続することができました。そういったアクションを他の人が見て、「自分も何かやるか」と思うきっかけにしてもらうことが重要だと思います。
続かないテックブログの対策
「社員を増やす」という目標に対して、テックブログが続かないという問題を解消したいとも考えていました。
そこで、会社のテックブログに個人ブログが自動で載せられるようにするプロジェクトを進めることにしました。
会社のテックブログとなると、記事投稿に対するの心理的ハードルが上がるものと思われます。また、エンジニアにおいて自分の技術記事は自分で開発したプロダクトに似た感情を持っている人も少なくないのではないでしょうか。個人的に、技術記事は自分の資産なので権利は手元においておきたいです。
この問題に対する対策が以下記事で書かれていました。 zenn.dev
上記記事を参考に個々人のアウトプットを自動的にテックブログへ集約する仕組みづくりを構築したいと考えていました。
ただ、これについては会社の経営方針変更により宙ぶらりんとなってしまっています。時間ができればやりたかった施策です。
2022年の抱負
やってきたことを色々と書いてきましたが、結果的には「社員全員の給料を上げる」という目標は達成できませんでした。
理由としては、採用にコミットできず結果につながらなかったことが挙げられます。
カジュアル面接にあたって、会社の情報を魅力的に伝える必要があるのですが、自分自身会社に対して「嫌いではないが好きでもない」という気持ちがあり、カジュアル面接に来てくださった方の「この会社に入りたい」という気持ちを刺激することができませんでした。採用に携わる業務を行うのであれば、会社を好きであるという気持ちは必須ではありませんが、非常に強い説得力が得られます。また、人間的に魅力があるかというとそうでもないため、「この人と一緒の会社で働きたい」という経路パターンも確保できていなかったと反省しています。
顧みて、採用業務にあたって自分にとって不足しているのは「人間もしくはエンジニアとしての魅力や、会社に対する強いこだわり」だという結論に至りました。そして自分の得意/苦手分野・趣味レベルで集中できる分野・キャリアプランのために伸ばすべき分野を分析した結果、今の会社にはマッチしていないと考え会社を辞めることにしました。マネージャーとして仕事をしていく上で何かしらの突出した能力もしくは実績がないとこの先辛いと考え、個人的に伸ばしたいスキルも今の会社では必要とされていなかったためです。これはネガティブな決断ではなく、自分の能力分析ができたことと次にやるべきことを達成するためのプラン変更と考え、意味のある成果だと感じています。
そもそもマネージャーではなくクリエイティブな領域の仕事がしたいという未練があったので、今年は心機一転でフロント・デザイン・3Dなどの学習に時間を割く予定です。一方で、チーム成果を最大化することのやりがいや難しさも経験できたため、PMとしての知識やアイデアは引き続きキャッチアップしていきます。
本記事で書いたのは個人的な経験談程度のものですが、今年からマネジメント業務を始める方の参考になれば幸いです。
それでは今年もよろしくお願いいたします。
参考文献
findy-code.io
メッセージを伝え続ける重要性を参考にし、「会社の目指す方向性」や「して欲しいこと」を常に1on1で伝えるようにした
tune.hatenadiary.jp
1on1や採用に関する活動を参考にし、業務の実行計画を整えた
scrumcommunity.pbworks.com
スクラムアンチパターンまとめ。コミュニケーションや対話を適切に行うための参考
medium.com
社員にとってのテックブログの価値観とモチベーションに関する考え方を参考
www.diamond.co.jp
組織課題を解決するために1on1は適しているか、また効果を最大化するための土台作りの参考
www.njg.co.jp
こちらから指示するのではなく、自分自身で課題を見つけ動けるようになってもらうための手法として参考
MarkdownファイルをブラウザでLive Reloadしながら編集する(Nodemon + BrowserSync)
会議の議事録、タスク管理、仕様の細かい備考など、メモというものは仕事に欠かせないものです。
メモの取り方は人それぞれですが、私は好んでMarkdown形式でメモを取ります。 Marddown形式であれば、Vimでシンタックスハイライトが効きますし、後々何かしらのブログサービスに記事として残す場合にそのまま貼り付ければ大概フォーマットに沿った形式となります。もしくはMarkdownはプレーンなテキストであり、それを何らかの形式に変換することが可能な場合があります。何らか、というのは全く想定していないのですが、何らかの形に変換したいときが来たときにスムーズに対応できる、という理由からとても心が安らぎます。話は逸れますが、同様に音楽ファイルなんかも可逆圧縮形式が好きです。今のところ実際に「何らかの形」に変換したことはないんですが。
しかし、Markdownテキストは通常のエディタで見ると、一定のフォーマットに則ったただのテキストです。
# 見出し1 ## 2021/3/7 本文
↑こんな感じです
ある程度の俯瞰しやすさはありますが、更にもう少し、分かりやすく見たいというときがあるのです。つまり、MarkdownテキストをHTMLで展開し閲覧したい。そんなときのために、MarkdownファイルをWebブラウザで確認しながら編集できる環境を作りました。
できあがったもの
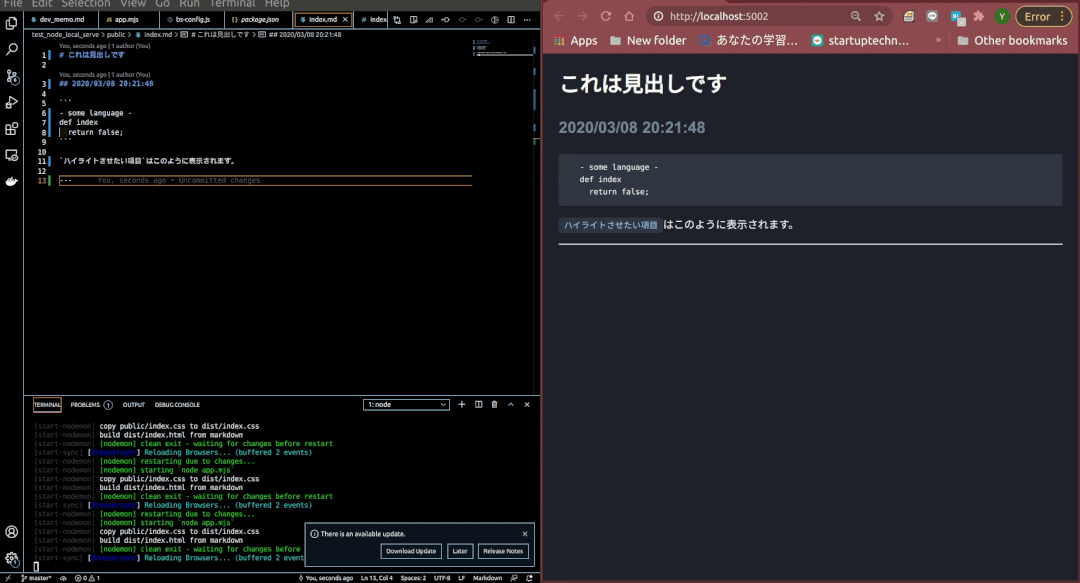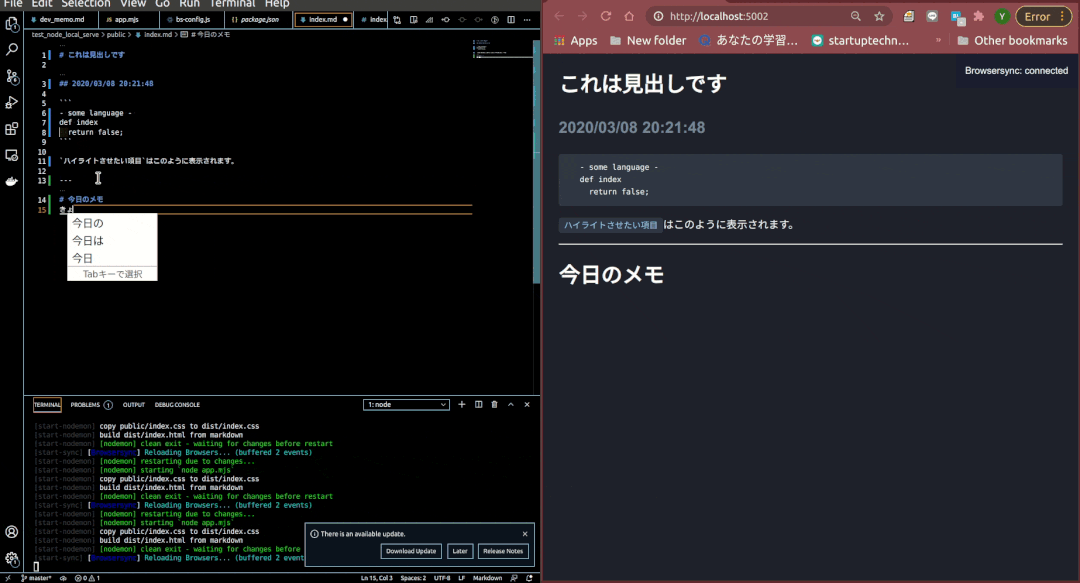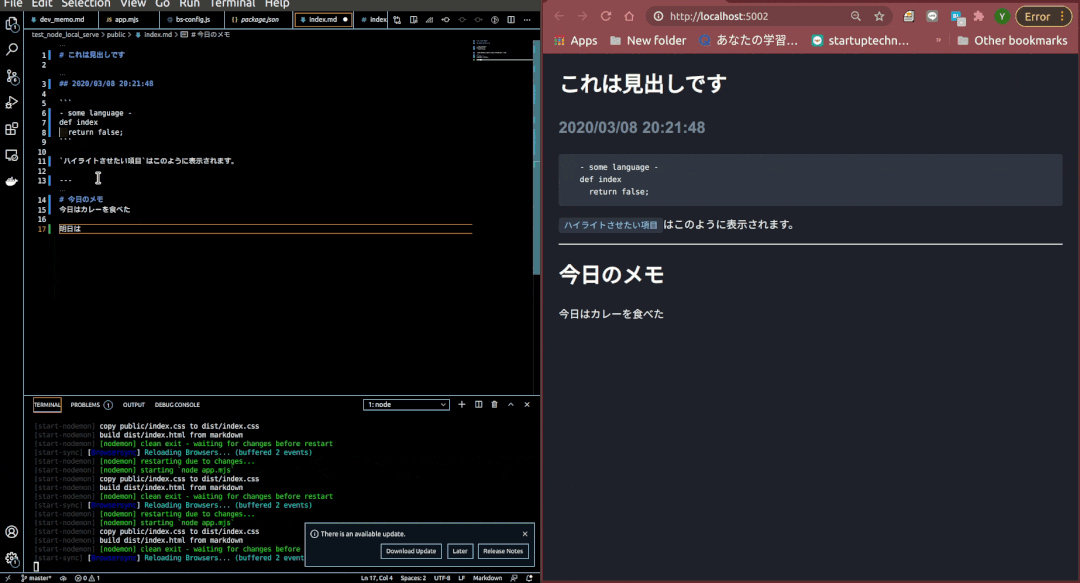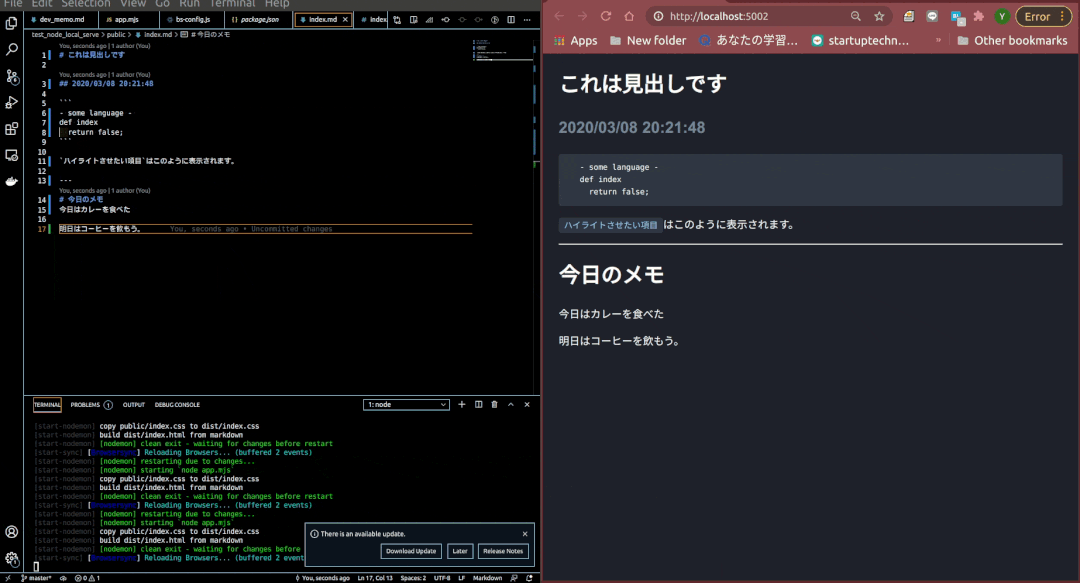
機能構造
仕組みとしては、
- 任意のHTMLファイルをローカルサーバーで監視し、Webブラウザで閲覧する
- 任意のMarkdownファイルが保存 / 編集されると、それをもとにしたHTMLファイルを生成する
- HTMLが生成されたことを検知し、ブラウザをリロードさせる
という単純な構造です。
Express(Node.jsのフレームワーク)を使えばその機能だけで作れてしまうらしいのですが、それだと利用するライブラリに無駄が多く勉強にもならないため、少し細かいスコープで機能を実装しました。といっても全てライブラリの機能で実現してしまったので勉強も何もないのですが。
以下、各種機能の実装方法です。
1. 任意のHTMLファイルをローカルサーバーで監視し、Webブラウザで閲覧する
これはBrowserSyncというライブラリで実現しました。
Node単体でも実現できるのですが、BrowserSyncは任意のファイルをserveし、ファイルの変更を検知するとブラウザをLive Reload(自動更新)することができます。
ちなみに私はブラウザの自動更新をHot Reloadと呼んでいたのですが、Hot ReloadはLive Reloadとは異なり、アプリケーションのstateを失わずに自動更新する機能のことのようです。
2. 任意のMarkdownファイルが保存 / 編集されると、それをもとにしたHTMLファイルを生成する
これはNodemonとmarkedというライブラリで実現しています。
Nodemonは任意のJSファイルを立ち上げ、任意のファイルの変更を検知するとJSファイルを再実行するライブラリです。
Nodemonで実行するJSファイルでは任意のMarkdownファイルを読み取ってHTMLファイルを生成する、という処理を行い、Markdownファイル編集されるたびにNodemonでJSファイルを再実行され、最新のMarkdownファイルからHTMLが再生成されるという流れになります。
(初めはこのNodemonでLive Reloadができるかと勘違いしており、無駄に時間を取ってしまいました)
markedはmarkdownテキストをHTMLに変換します。
markedはサニタイズをしないとXSSの脆弱性を持つためリポジトリ上でオススメされているDOMPurify(もしくは他のライブラリ)でサニタイズを行う必要があります。
(今回のように自分で作ったファイルを自分で開く分には気にしなくて良いと思います)
3. HTMLが生成されたことを検知し、ブラウザをリロードさせる
これも先に述べたBrowserSyncというライブラリの機能を使います。
どのファイルを検知するかは予め設定ファイルを書いておく必要があります(もしくはCLIでの実行時に引数で指定する必要があります)。
以下セクションにて、ファイル全体の細かいコードを書いていきます。
ファイルの全体像
- dist/ - node_modules/ - public/ - index.html - index.css - app.mjs - bs-config.js // BrowserSyncの設定ファイル - nodemon.json // Nodemonの設定ファイル - package.json - yarn.lock
.mjs という、人によっては奇妙な拡張子がありますが、今回利用したのはこれを使うことでどういう考慮をする必要があるか(もしくは考慮をする必要がなくなるか)を確認するためです。様々なデメリットを考慮すると .js の方が良いと結論づけます。以下に .mjs にまつわる背景が記述されていますが、正直今の私にとっては「そうですか」という感想しか湧きませんでした。つまるところ、よく分からなかったです、すみません。
app.mjs
import marked from 'marked';
import fs from 'fs';
const headHTML = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Markdown Browser</title>
<link rel="stylesheet" href="index.css" type="text/css">
</head>
<body>
`
const footHTML = `
</body>
</html>
`
// 再実行されるたびにファイル作成処理が走るので、差分がない場合は無視したい
fs.readFile('public/index.md', 'utf-8', (errRead, data) => {
if (errRead) { throw errRead; }
const bodyHTML = marked(data);
const allHTML = headHTML + bodyHTML + footHTML
fs.writeFile('dist/index.html', allHTML, function (errWrite) {
if (errWrite) { throw errWrite; }
console.log('build dist/index.html from markdown');
});
});
// アクセスするたびにファイル作成処理が走るので、差分がない場合は無視したい
fs.copyFile('public/index.css','dist/index.css', (err) => {
if (err) { throw err; }
console.log('copy public/index.css to dist/index.css');
});
やっていることは単純で、実行された際に、public/index.mdを読み込み、それをもとにdist/index.htmlを生成します。
ついでにpublic/index.cssファイルもdist/index.cssとしてcopyしています。
nodemon.json
{
"ignore": [
".git",
"node_modules/**/node_modules"
],
"watch": [
"public/index.md",
"public/index.css"
]
}
Nodemonの設定ファイルです。
これも非常に単純で必要ないファイルを無視し、public/index.mdもしくはpublic/index.cssに変更があった場合にapp.mjsを再実行する仕組みとしています。
bs-config.js
module.exports = {
"watch": ["dist/index.html"],
"server": {
baseDir: "dist",
index: "index.html",
},
port: 5000,
};
BrowserSyncの設定ファイルです。
これも単(以下略)
package.json
{
...
"scripts": {
"start": "concurrently 'yarn:start-*'",
"start-nodemon": "yarn nodemon app.mjs",
"start-sync": "yarn browser-sync start --config bs-config.js"
},
...
}
npm-scriptsでNodemon用のサーバーとBrowserSync用のサーバーを並行で起動させています。
concurrentlyはnpm-scriptを簡単に記述するためのライブラリで上記のように start-* と書くことでprefixが start- のコマンドを簡単に指定することができます。
(おそらくもっとトリッキーな使い方ができそうです)
この状態で
$ yarn start
とすると、自動的にブラウザのページが開きます。
index.cssはお好みで設定してください。
表示の見た目が自分好みになれば、メモがもっと楽しくなるはずです。
多分。
振り返り
BrowserSyncのProxyモードで簡単にできるかと思ったのですが、ProxyモードだとProxyしている場合Live Reloadはされないようでした。こちらの設定ミスかも?また、BrowserSyncではきちんとしたHTMLではないとLive Reloadされず、index.htmlにプレーンなテキストを書いても上手く反映されなかったためそこでかなり時間を取られました。本当はLive Reloadを自分で実装したかったのですが、力量が足りず断念。単純に基礎知識が足りないのでnpmパッケージのコードリーディングが全くできませんでした。WebSocketを使えば可能だとは思うので、まずはWebSocketの基本から学ぶことにします。拡張子ごとのシンタックスハイライトも入れたいですが、さすがにライブラリで良いかな……。メモの作成や一覧表示なんかもCLI上でできるようにしたいので、そこができればツールとして公開したいですね。みなさんもオレオレメモ環境を作ってどんどんメモ & 知見を増やしていきましょう。
OpenMediaVaultの導入後にWLANがつながらなくなる問題をCLI上で解決
OpenMediaVault(OMV)をRaspberry Pi OS Liteにインストールしたのですが、その後Wi-Fiにつながらなくなりました。
解決策を備忘録として残しておきます。
前提条件
- Raspberry Pi OS Lite
- Raspberry Pi 3B
概要
ラズパイ上でOMVのインストール pi@raspberrypi:~ $ wget -O - https://github.com/OpenMediaVault-Plugin-Developers/installScript/raw/master/install | sudo bash
上記コマンドを打ったあと自動的に再起動されるのですが、それまで接続されていたWi-Fiにつながらなくなりました。
OMV側のネットワークインターフェース設定を変更する
以下コマンドを打つことでCLI上からOMVの設定画面を表示できます。
pi@raspberrypi:~ $ sudo omv-firstaid

1. Configure network interface を選択します。
wlan0 を選択して、ウィザード形式で設定を進めます。
これで無線につながるようになりました。
Raspberry Pi 3Bの初期設定メモ(Headless Setup)
あけましておめでとうございます。
お正月ですが外出するのもアレなので、家でできる趣味事としてラズパイを買いました。
新年最初の記事ですが単なるメモ記事となります。
初めてラズパイ触るので基本的な内容となりますが、同じく初心者諸兄の参考となれば幸いです。
前提条件
あまり関係ないですが、事前準備はUbnutu(20.04)上で行っています。
やること
Raspberry Pi 3BにRaspberry Pi OS Liteをインストールする
ディスプレイなしで初期設定する
2020年5月に正式名称がRaspbianからRaspberry Pi OSへ変更されました。 内容としてはRapbian導入の流れと違いはないと思います。
用意するもの
- ラズパイ本体(Raspberry Pi 3B)
現在の型は4まで出ていますが、自分の用途ではスペックを必要としないため、少しだけ消費電力の少ない3を選びました。 (後から知ったのですが、3B+であれば無線LANが5GHzに対応してるので、そっちを買っておけば良かった)
- 電源アダプタ(USB Micro-B)
出力は5V・2A〜3A程度を目安に選べば良いと思います。
OSをインストールするために用意します。 自分は適当に32GBを選びましたが、容量やI/O速度を気にする人はしっかりと選ぶことをオススメします。
他、用途によってはディスプレイ・ケーブルなど必要になりますが、プライベートネットワークからSSH接続して設定ができるので、上記のものだけで設定可能です。
1. Raspberry Pi 3BにRaspberry Pi OS Liteをインストールする
Raspberry Pi Imagerのインストール
ラズパイをmicroSDにインストールするために、自分のPC(not ラズパイ)にRaspberry Pi Imagerをインストールします。 Raspberry Pi Imager上から必要なイメージファイルもダウンロードできます。
Raspberry Pi OS Liteリリースノート
https://downloads.raspberrypi.org/raspios_lite_armhf/release_notes.txt
2. ディスプレイなしで初期設定する
SSH接続できるようにmicroSDにファイルを追加
bootディレクトリ上に ssh というファイル名のファイル(内容は空)を追加します。
次に接続するWi-Fiの情報を記載するファイル wpa_supplicant.conf を追加します。
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
country=JP
network={
ssid="<Name of your wireless LAN>"
psk="<Password for your wireless LAN>"
}
ラズパイ起動
ラズパイにmicroSDを挿入し、電源アダプタをつなぎます。 電源をつなげると自動的に起動します。
電源を入れると上記追加したファイルをもとにWi-Fiに自動接続されます。 すぐには起動しないので5分ほど待ちましょう。
意図通りネットワークにつながっているかどうか調べるには nmap というツールが便利です。
$ sudo apt install nmap
ホストと同一ネットワーク内のクライアントを調べる $ nmap -sP 192.168.0.0/24 ... Nmap scan report for 192.168.0.10 Host is up (0.0081s latency). ...
指定のIPアドレスで接続しているクライアントのOSを調べる $ sudo nmap -O 192.168.0.10 ... MAC Address: B8:27:EB:3E:60:45 (Raspberry Pi Foundation) ... ラズパイが接続されていれば上記のように表示される
SSH接続
同一ネットワークに接続されていれば ID: pi, PASS: raspberry で接続できるようになります。
$ ssh pi@raspberrypi.local
もし名前から探せない場合はIPアドレス指定でも試してみるのも良いと思います。
$ ssh pi@192.168.0.10
Wi-Fiパスワードの暗号化
以下、ラズパイ上での操作です。
SSIDとパスワードを入力することで暗号化されたパスワードが表示されます。
pi@raspberrypi:~ $ sudo sh -c 'wpa_passphrase "<接続先のSSID>" "<平文のパスワード>"'
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
country=JP
network={
ssid="<Name of your wireless LAN>"
#psk="<Password for your wireless LAN>"
psk=暗号化されたパスワード
}
それをもとに /etc/wpa_supplicant/wpa_supplicant.conf を編集します。
再起動してちゃんとWi-Fi接続するかどうか確認しましょう。
pi@raspberrypi:~ $ sudo reboot
数分待った後、設定が正しくできていれば再度SSH接続できるようになるはずです。
最新の状態にアップデート
pi@raspberrypi:~ $ sudo apt update
pi@raspberrypi:~ $ sudo apt upgrade
必要なパッケージのインストール(オプション)
必要な方だけ。私はとりあえずエディタとしてvimを入れます。
pi@raspberrypi:~ $ sudo apt install vim
時刻設定・locale設定
pi@raspberrypi:~ $ sudo vim /etc/ntp.conf
pi@raspberrypi:~ $ sudo /etc/init.d/ntpd restart
その他設定
その他色々と設定する項目がありますがいったんここまで。
以下ページを参考にさせていただきたいと思ってます。 qiita.com
ラズパイのコンフィグ画面は以下コマンドで開くことができます。
pi@raspberrypi:~ $ sudo raspi-config
メモ_UbuntuでのR言語導入・RMecab導入
前提条件
$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.5 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.5 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionic
R言語インストール
$ sudo apt update $ sudo apt install r-base $ R --version R version 3.6.3 (2020-02-29) -- "Holding the Windsock" ...
Rmecab
MeCabのインストール
$ sudo apt-get install -y mecab libmecab-dev mecab-ipadic-utf8 $ mecab --version mecab of 0.996
RMeCabのインストール
$ R
> install.packages('RMeCab')
> packageVersion("RMeCab")
[1] ‘1.4’
Ubnutuだと下記エラーメッセージが出てコンパイルエラーが出るかもしれない。
/usr/lib/R/lib -lR /usr/bin/ld: cannot find -lmecab collect2: error: ld returned 1 exit status /usr/share/R/share/make/shlib.mk:6: recipe for target 'RMeCab.so' failed make: *** [RMeCab.so] Error 1 ERROR: compilation failed for package ‘RMeCab’
自分の場合は上述したようにlibmecab-devのような関連ライブラリを入れることで解消できた。
その他
# パイプ演算子%>%を使ってパイプ処理ができるようになる library(magrittr) # 文字列処理の関数を持つパッケージ(baseパッケージのものより使いやすいらしい) library(stringr) # tibble形式(data frameオブジェクトを拡張した形式)で取り扱うためのパッケージ library(tidytext) # データフレーム(data.frameクラスを持つリスト)を操作するのに適したパッケージ library(dplyr)
変数についている$は何?
-> hoge$bar
-> データフレーム名$列名のようにデータフレームの列を参照するのに利用する
tibbleのメリットについて
ある日tidyと一緒に: tidyverseは厳しいがとても優しい
一人スクラムをしようとしてスクラムについて学習してやっぱりやめた話
カイゼン・ジャーニーという本を読み、言及されていたスクラムフレームワークについて興味が湧いています。
このスクラムというフレームワーク、個人での開発にも適用できないかと思い色々と調べていたのですが、やはり同じようなことを考える人もいるようで、実践されているブログをちらほら見かけました。
自分も一人スクラムをやっていくぞと思い、スクラムについて学習しつつ考えてみたのですが、スクラムへの理解を深めるごとに一人スクラムの効果について懐疑的になったため、私の考える一人スクラムについての問題点をまとめることにしました。
スクラムを一人でやるとうまみが少ない
スクラムフレームワークとはそもそもチームでの作業管理を行うためのフレームワークです。 スクラムのセオリーとして重要視されているのが 「透明性 (Transparency)」・「検査 (Inspection)」・「適応 (Adaptation)」 という三つの要素であり、これらをテーマに一人スクラムを考えてみます。
透明性 では「プロジェクトで利用する用語」や「完成の定義」などをチーム内で共通化するべきだと説いています。ただ、一人で行なっている時点で共通化はされている(できない)ため、スクラムの重要な面がスポイルされることになるでしょう。
問題の検知を行うための 検査 も一人スクラムでは非常に難しいものとなります。というのも、作業を行う人間が自分一人であれば、検査を行う人間も自分一人となるのです。作業担当者とレビュアーが同一人物であると言えば、どれだけ不毛なことイベントとなるかは明白でしょう。
ただ一つ適応については問題ありません。振り返りを行うことで、進捗の問題に対する改善点を踏まえ、次回のスプリントに臨むことが可能です。 さて、一人でスクラムを行なった場合「振り返りを行うことで改善を繰り返すことができる」ようになります。やりました! ただ、これってスクラムでしょうか?どちらかというとアジャイルな気がします。
スクラムでの役割分担の重要性
スクラムではいくつかの役割を設定しています。 プロダクトオーナーは開発チームから生み出されるプロダクトの価値の最大化に責任を持ちます。 スクラムメンバーは「完成」したプロダクトインクリメントを届けることのできる専門家です。 スクラムマスターはスクラムガイドで定義されたスクラムの促進と支援に責任を持ちます。
ここで重要なのは、スクラムでは特定の役割の人間が他の役割の作業を行うことを認めていません。例えば、プロダクトオーナーが開発したり開発の仕方に口を出すのは望ましくありません。プロダクトオーナーはプロダクトの価値の最大化に責任を持っており、その役割に集中することでプロダクト価値を保証することができることがスクラムとフレームワークの存在意義の一つとなります。フレームワークとは特定の目的を達成するための骨組みであり、それらを守ることで初めて意味が生まれます。
もちろん、目的やチーム背景によってはそれらルールを変更する必要はあるかもしれませんが、変更するたびに目的達成のための複雑なファクターにほころびが出る可能性があることを忘れてはなりません。一人スクラムでは役割がないため、複雑なタスクに対応するためのスクラムフレームワークの意味合いがかなり薄まることになります。
ただただ、スクラムの練習をしたいということであれば、一人でそれぞれの役割を分担することでその目的は達成されます。 プロダクトオーナーしての作業を行うときは「俺はプロダクトオーナーだ......」と心の中で唱え、プロセスの優先順位を変更する場合には「プロダクトオーナー!優先順位を変えたいのですが。」「フムフム、それはどういう理由かね?」という一人芝居を行えば、素晴らしい練習になるでしょう(本当に練習になるはずです)。
一人スクラムで期待できること
一人でスクラムを行うことの問題点を上述しましたが、それでも得られるものはあるかと思います。
スプリントプランニングではこれからのスプリントでどういったことをするべきかを決めます。私が通っていた学校では夏休みには常に計画表を作るように言われていました。計画を立てるのは本当に大事なことなのです(それに気がついたのは学校を卒業して仕事でこっぴどく怒られた後でしたが)。
計画ができたらスプリントの期間を決めてプロセスをガンガンこなしていきましょう。スプリントのたびに進捗の確認を行い、必要であれば見直しを行います。
デイリースクラムを毎日行えば、問題があったとしてもすぐに調整を行うことができます。素早い改善は素早い完了につながります。
さて、一人スクラムでも得られるものがあることがわかりました。「計画と定期的な振り返りと日々の現状確認を行う」ことができればバッチリです。ただ、これってスクラムでしょうか?
こう考えると、スクラムというものはチームのための複雑な問題解決のフレームワークだとわかります。 一人でスクラムをやったとしても、それはスクラムの用語を使った丁寧な作業 なのではないでしょうか。スプリントプランニングもスプリントもデイリースクラムもチームでの知識共有・問題解決・作業最適化などを目的としたものであり、それ自体の行為がスクラムではないのだと私は思います。
一人スクラムの可能性
スクラムを踏襲した一人スクラムについて考えましたが、私には思いつきませんでした。 もしかすると一人スクラムをされている方で「こうすればスクラムのうまみを保ちながら作業できるよ!」という意見があればぜひ教えてもらえると嬉しいです。 ただ、やはりプライベートでのイベントも生産性をハックしていきたいという気持ちはあるので、個人用のオレオレフレームワークを作っていこうという気持ちが高まりました。自分のためのプロセスマイクロフレームワーク、作っていきましょう。